Paginierung mit rel=”next” und rel=”prev”

UPDATE zum Thema Paginierung mit rel=”next” und rel=”prev”:Wie vielleicht einige schon mitbekommen haben, hat Google die Bombe platzen lassen. Am 21. März twitterte der Google Webmaster-Account folgendes:
Spring cleaning!
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what’s best for *your* users! #springiscoming pic.twitter.com/hCODPoKgKp— Google Webmasters (@googlewmc) March 21, 2019
John Müllers Tweet, Webmaster von Google, feuerte die Nachricht noch weiter an:

So, zurück auf Anfang und alle rel next/prev-Auszeichnungen löschen? – Eher nicht. Denn auch wenn Google der Spitzenreiter der Suchmaschinen ist, optimieren SEOs und Webseitenbetreiber Webseiten nicht nur für sie, sondern noch für viele weitere Suchmaschinen, wie beispielsweise Bing.
We’re using rel prev/next (like most markup) as hints for page discovery and site structure understanding. At this point we’re not merging pages together in the index based on these and we’re not using prev/next in the ranking model. https://t.co/ZwbSZkn3Jf
— Frédéric Dubut (@CoperniX) March 21, 2019
Auch wenn Google die Verweise rel=”next” und rel=”prev” seit Jahren nicht mehr und zukünftig weiterhin nicht nutzen, bedeutet dies nicht, dass die bisherigen Bemühungen für die Implementation der Markups für die Katz´waren.
Darum mein Ratschlag: Wenn ihr rel=”next” und rel=”prev” korrekt nutzt, lasst es drinnen. Schaden wird es eurer Webseite nicht. Und wenn euch Suchmaschinen abseits von Google wichtig sind, nutzt es weiterhin. Ist die Auszeichnung jedoch bisher fehlerhaft, dann sollte man diese dennoch korrigieren oder entfernen. Es besteht aber, nicht wie noch vor einigen Wochen gedacht, keine Notwendigkeit diese für die Auszeichnung der Seitenreihenfolge zu nutzen.
Und jetzt weiter mit dem Artikel ;)
Zwar ist die Thematik rund um Paginierung, oder auch im englischen Pagination, für viele SEOs und Webseiten-Betreiber ein alter Hut, dennoch gibt es hierzu oft noch Fragen oder unterschiedliche Meinungen darüber wie man “richtig” paginiert. Und richtig ist es dann, wenn Suchmaschinen wie Google alle Inhalte finden, crawlen und nach Bedarf indexieren kann. Im folgenden Beitrag möchten wir Euch die verschiedenen Varianten der Paginierung vorstellen und auf die häufigsten Fehler hinweisen, damit Ihr diese vermeiden könnt. Los geht´s!
Was ist eine Paginierung?
Unter einer Paginierung versteht man die Seitennummerierung auf Webseiten bei zusammenhängendem Content. Paginierungen kommen vor allem bei Shops, Webseiten mit sehr langen Artikeln, Blog-Einträgen oder Foren zum Einsatz. Also überall da, wo aus Usability-Gründen Content über mehrere Seiten aufgeteilt ist. Einer dieser Gründe ist die Performance, denn: Eine Seite mit sehr viel Content, möglicherweise noch vielen Bildern oder Videos, schneidet in einer Performance-Analyse deutlich schlechter ab, als wenn man die Inhalte auf verschiedene Seiten verteilt. Darüber hinaus sorgt die Aufteilung auf mehrere Seiten auch für eine bessere Übersichtlichkeit. Jeder menschliche User wird aufgrund der Seitennummerierung verstehen, dass die paginierten Seiten zusammenhängen. Zudem versteht dieser problemlos die Reihenfolge, sprich bei welcher Seite es sich um Seite 1 handelt. Für die Suchmaschine ist dieser Vorgang viel komplizierter.
Warum sind rel=”next” und rel=”prev” für SEO so wichtig?
Und hier liegt das Problem: Kein Suchmaschinen-Bot wird fehlerfrei zusammenhängende Seiten zuordnen können und erkennen, bei welcher Seite es sich um Seite 1, im Bestfall die Einstiegsseite für den User, handelt. Anders als ein Mensch ließt ein Crawler jede Seite individuell, weshalb es ihm aufgrund der Schaltfläche mit der Seitennummerierung nicht möglich ist, Seite 1 bis x in korrekter Relation zu setzen. Im schlechtesten Fall werden dann die einzelnen Seiten, die eigentlich zusammengehören als Duplikat gewertet (da sie zumindest sehr ähnlich sind) und machen sich gegenseitig Konkurrenz. Sprich: Google würde zwar alle paginierten Seiten finden und indizieren, jedoch besteht die Wahrscheinlichkeit, dass der User unter Umständen nicht über die Suchergebnisse auf Seite 1 einsteigt, sondern auf Seite 2-x, da Google deren Zusammenhang nicht kennt.
Um dieses Problem zu lösen, wurden 2011 die HTML-Attribute rel=”next” und rel=“prev” erfunden. Mit diesen ist es möglich die Beziehung der Komponenten-Seiten für den Crawler darzulegen. Spricht ein SEO über Paginierung, meint er daher nicht nur die Schaltfläche, mit dieser man als User auf Seite 2 beispielsweise kommt, sondern die Attribute rel=”next” und rel=“prev”.
Verzichtet man auf die Auszeichnung der Paginierung oder ist einem dabei ein Fehler unterlaufen, muss man sich auf die Suchmaschine verlassen. Denn ohne rel=”next” und rel=”prev” muss Google sich die Reihenfolge eigenständig erschließen und das kann verständlicherweise auch Mal schief gehen. Darum ist die Verwendung der Attribute zu empfehlen, um dem Crawler genaue Hinweise über die Beschaffenheit der Seite zu liefern. (Wichtig: Die Angaben rel=“next” und rel=”prev” sind wie beim Canonical-Tag nur Hinweise, keine absoluten Anweisungen an die Google sich halten muss.)
Wie bei einer internen Verlinkung ist es hier wichtig, dass Google und Co …
- alle Seiten unter Seite 1 findet,
- versteht, bei welcher Seite es sich um Seite 1, Seite 2 usw. handelt
- diese richtig in einen Kontext /Reihenfolge setzt
- alle Inhalte und Links auf den Seiten crawlen kann und
- nur Seite 1 indexiert wird, sodass der Nutzer nicht über die SERPs auf Seite 5 einsteigt
Und für all diese wichtigen Punkte sind die Attribute rel=”next” und rel=”prev” erfunden worden. Bei korrekter Verwendung signalisiert man dem Bot
- die genaue Reihenfolge der Seiten,
- sorgt dafür, dass alle Seiten gefunden und gecrawlt werden können und
- welche die erste Seite ist und nur diese in den SERPs erscheint.
Es sind mir zwar keine Fälle bekannt, aber es soll wohl schon passiert sein, dass trotz fehlerfreier Paginierung mit next und prev nicht nur Seite 1, sondern auch die folgenden Seiten indexiert wurden. Dies stellt jedoch die Ausnahme dar.
Wie paginiert man suchmaschinenfreundlich?
Wie schon erwähnt nutzt man für eine suchmaschinenfreundliche Paginierung die Attribute rel=”next” und rel=“prev”. Alternativ zu rel=“prev” erkennt Google auch die Variante rel=”previous” an. Die Auszeichnung wird ausschließlich im <head>-Bereich, nicht in den <body>, der Webseite vorgenommen.
Anders als bei Canonical-Auszeichnung zeichnet man auf der jeweiligen Seite nicht die eigene URL aus, sondern die Seiten, die davor und/oder danach folgen. Und da Beispiele immer verständlicher sind, folgt hier eins.
Nehmen wir an, wir haben einen sehr langen Blog Artikel, den wir auf drei Seiten aufteilen möchten. Die URLs sähen wie folgt aus:
https://beispiel.de/blog/artikel/seite1.html
https://beispiel.de/blog/artikel/seite2.html
https://beispiel.de/blog/artikel/seite3.html
Auf der ersten Seite https://beispiel.de/blog/artikel/seite1.html stände im <head> Bereich folgende Auszeichnung:
<link rel=”next” href=”https://beispiel.de/blog/artikel/seite2.html”>
Hier wird nur das next-Attribut verwendet, um auf Seite 2 zu verweisen. Das prev-Attribut wird nicht gebraucht, da es keine vorangehende Seite gibt. Bei der Auszeichnung auf Seite 2 kommen beide Attribute zum Einsatz. Hier zeichnet man zum einen die vorangehende Seite aus, hier Seite 1, und die folgende Seite, hier Seite 3.
<link rel=”prev” href=”https://beispiel.de/blog/artikel/seite1.html”>
<link rel=”next” href=”https://beispiel.de/blog/artikel/seite3.html”>
Da es sich bei Seite 3 um die letzte Seite handelt, wird hier nur das prev-Attribut verwendet, da keine weitere folgen wird.
<link rel=”prev” href=”https://beispiel.de/blog/artikel/seite2.html”>
Seite 1 verweist somit auf Seite 2, die wiederum auf Seite 1 und 3 verweist. Seite 3 verweist nur auf Seite 2. Dies kann man beliebig vielen zusammenhängenden Seiten fortführen. Also ziemlich simpel ;)
Wie verwende ich Canonicals und Meta Robots auf paginierten Seiten?
Jetzt wo wir die Auszeichnung für die Paginierung haben, folgt noch das beliebte Canonical und die Meta Robots-Angaben. Bei einer Standard-Paginierung haben alle Seiten ein selbstreferentielles Canonical und die Robots-Angaben index, follow. Alle drei Auszeichnungen sind zusammen im <head> Bereich – nicht vergessen.
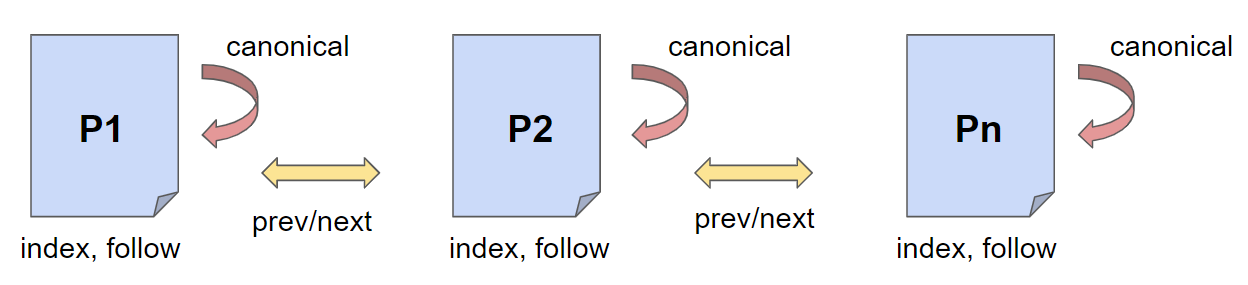
Eine beliebte Methode ist die Verwendung von noindex in den Meta Robots Angaben auf den Seiten 2 bis n.
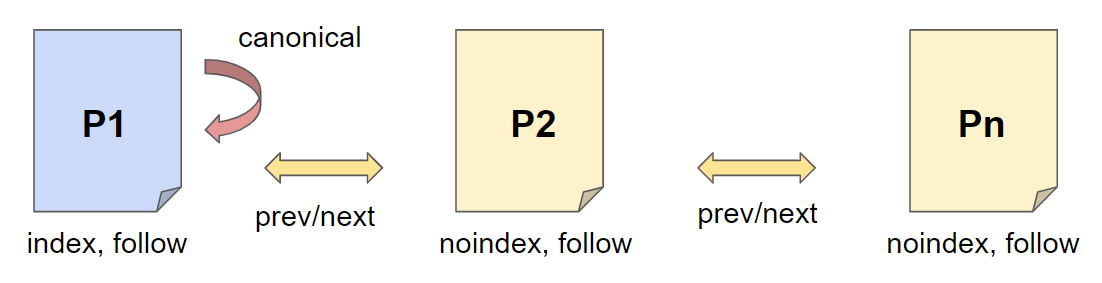
Hiermit möchte man verhindern, dass der User auf einer anderen Seite als der ersten Seite einsteigt. Diese Methode ist jedoch nicht zu empfehlen! Warum?
- Inhalte auf Seite 2 bis n sind durch das noindex in der Regel nicht indexiert und somit nicht für die Erhebung der Suchergebnisse relevant. Hier verschenkt man viel Potential.
- Ein noindex, follow führt langfristig zu einem noindex, nofollow. Die Paginierung wird dies nicht verhindern.
- Auf Seiten mit einem noindex wird Google langfristig keinen Links mehr folgen, sprich es können wichtige Ranking-Signale verloren gehen
Häufiger Fehler bei Paginierung: Canonical auf paginierten Seiten
Ein häufiger Fehler bei der Verwendung von rel=”canonical” in Verbindung mit paginierten Seiten ist, alle Seiten ab Seite 2, z.B. https://beispiel.de/blog/artikel/seite2.html ein verweisendes Canonical auf Seite 1 haben.
Der Grund: Der Webseitenbetreiber möchte, dass lediglich Seite 1 indexiert wird und der User nicht über die Suchergebnisse (SERPs) auf Seite 2 gelangt. Mit einem Canonical signalisiert man Google, welche Seite indexiert werden soll und bei welcher Seite es sich um ein Duplikat einer Seite handelt, weshalb nicht beide indexiert werden sollen.
Bei Seite 2 handelt es sich üblicherweise nicht um ein Duplikat der ersten Seite, auch wenn sich in einem Shop die Kategorie-Seiten ähnlich sind. Daher ist ein Canonical hier der falsche Weg und kann dazu führen, dass Meta-Angaben auf der gesamten Webseite ignoriert werden, da die Suchmaschine den Angaben nicht vertrauen kann. Zudem wertet Google ausgehende interne und externe Links von Seiten mit einem verweisenden Canonical nicht. Wenn man bei Paginierung Canonicals verwenden, können diese auf Seite 1 bis Seite n gesetzt sein, wobei diese dann ausschließlich selbstreferenziell sind, d.h. die Seite verweist mit einem Canonical auf sich selbst.
Möchte man keine inkorrekten Canonical setzen, aber dennoch nicht riskieren, dass die View-all-page mit Seite 1 in den SERPs konkurriert, gibt es noch die Möglichkeit die paginierten Seiten auf noindex, follow zu setzen. Hier hat nur die View-all-page ein Canonical auf sich selbst. Diese Methode ist nur sinnvoll, wenn die View-all-page eine gute Performance aufweisen kann. Hat sie diese nicht, schadet man sich nur selbst, da Content auf schlecht performenden Seiten weniger gut ranken. Eine Aufteilung der Inhalte in einzelne Komponenten wäre dem Ranking dann hier förderlicher.
Kombination aus Paginierung und einer View-all-page
Eine sehr beliebte Alternative zu der Standard-Paginierung ist eine View-all-page oder auch Komplettansicht. Auf dieser Seite ist der gesamte aufgeteilte Content zu finden. Diese hat je nach Content-Art, beispielsweise mit vielen Bildern, eine schlechtere Pagespeed-Performance.
Hier gibt es nochmals verschiedene Varianten, wie man diese auf seiner Webseite integriert. Wie auf der folgenden Abbildung kann man sowohl die View-all-page als auch die paginierten Seiten alle über die Robots-Angaben indexieren. Über die next/prev-Angaben werden alle Seiten in Relation gesetzt, wobei hier die View-all-page die Seite 1 wäre. Die paginierten Seiten verweisen dabei mit einem Canonical auf die View-all-page und stellen sich somit als Duplikate dar.
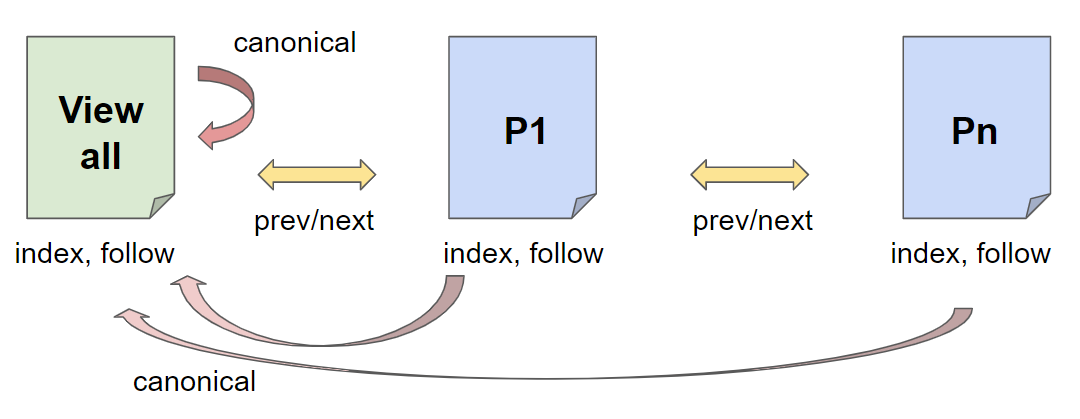
Vorteil: Alle Seiten werden vom Bot gefunden, indexiert und im Optimalfall rankt nur die View-all-page.
Nachteil: Das Canonical ist theoretisch falsch, da es sich bei den paginierten Seiten um keine Duplikate der View-all-page handelt.
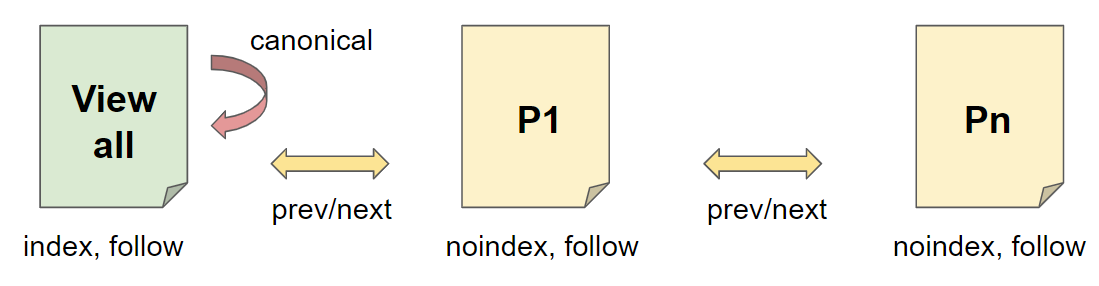
Vorteil: Alle Inhalte sind auf View-all-page und werden indexiert. Seite 1 konkurriert aufgrund der Robots-Angabe noindex, follow nicht mit der View-all-page.
Nachteil: Ein langfristiges noindex führt dazu, dass die Signale der Seite nicht mehr berücksichtigt werden, auch wenn ein follow-Attribut gesetzt ist.
Paginierung mit Infinite Scrolling
Seit einigen Jahren gibt es das sogenannte Infinite Scrolling, unendliches Scrollen. Hierbei kann man den Inhalt einer Seite, den man sonst auf mehrere Seiten aufteilen würde, auf einer Seite darstellen. Statt den Seitenumbrüchen, bzw. dem Weiterblättern, kann der User dank JavaScript immer weiter nach unten Scrollen und gelangt so auf Seite 2 bis n. Die Inhalte der weiteren Seiten werden ab einer bestimmten Scrolltiefe abgerufen und der ersten Seite automatisch hinzugefügt.
Aus Usability Sicht (UX) ist diese Seitenvariante zu empfehlen, jedoch können Bots, wie der Googlebot, ein solches Userverhalten nicht nachstellen. Das heißt, dass alle Seiteninhalte, die nur mit JavaScript geladen werden können, im schlechtesten Fall vom Bot nicht gefunden und indexiert werden können.
Die Lösung ist eine gleichwertige paginierte Seite für Crawler zu schaffen, die dieser ohne JavaScript erreichen kann. Dies funktioniert mit der Implementierung eines PushStates. PushState ist Teil der HTML 5 History API und emuliert das Nutzerverhalten, wie das aktive blättern einer Seite oder einen Klick. Hierbei wird die Adressleiste mit JavaScript automatisch aktualisiert, um der angegebenen URL zu entsprechen, ohne dass die Seite neu laden muss. Diese Variante muss gründlich vorab getestet werden. Zudem sollte man in regelmäßigen Abständen kontrollieren, ob die Inhalte auf den unteren Seiten von Google erkannt und indexiert werden. Vergleicht man Infinite Scrolling mit den Methoden der Standard-Paginierung, fällt auf, dass beim Infinite Scrolling die Paginierung nach wie vor angewandt wird, jedoch mit einer Portion User Experience ergänzt.
Ein schönes Beispiel wie eine SEO-freundliche Webseite mit Infitive Scrolling aussehen sollte, ist http://scrollsample.appspot.com/items. Schaltet man über das Chrome Developer Tool JavaScript aus, sieht man, dass eine Schaltfläche erscheint, die das Umblättern zu den folgenden Seiten ermöglicht. Eine schnelle Möglichkeit um das Verhalten von einem Crawler simulieren zu können.
Auf der ersten Seite http://scrollsample.appspot.com/items verweist das Canonical auf sich selbst und es wird über das rel=”next” Attribut die URL der zweiten Seite angegeben.
<link rel=“canonical“ href=“/items“>
<link rel=“next“ href=“/items?page=2″>
Im <head> der zweiten Seite http://scrollsample.appspot.com/items?page=2 ist ebenfalls ein selbstreferentielles Canonical und der Verweis auf die erste und dritte Seite:
<link rel=“canonical“ href=“/items?page=2″>
<link rel=“next“ href=“/items?page=3″>
<link rel=“prev“ href=“/items“>
Alle weiteren Seiten folgen diesem Beispiel. Auf der letzten Seite ist selbstverständlich nur ein rel=“prev” Attribut.
Fazit: Wie paginiert man am besten?
Wie man anhand der vielen Beispiele gesehen hat, führen viele Wege zum Ziel. Darum ist eine pauschale Antwort für alle Anwendungsfälle nicht möglich. Jedoch kann man je nach Größe der Webseite und Seiten-Performance eine Empfehlung geben:
Möchte man sowohl dem User als auch der Suchmaschine gefallen, empfiehlt sich eine Paginierung in Kombination mit Infinite Scrolling. Diese Lösung ist sowohl SEO- als auch UX-konform und bietet bei korrekter Anwendung nur Vorteile. Die Ladezeit wird aufgrund der Standard niedrig gehalten, der Crawler wird alle paginierten URLs finden und die Reihenfolge verstehen und der User wird die unkomplizierte Bedienung zu schätzen wissen. Diese Methode ist jedoch die aufwendigste, weshalb hier der Kosten-Nutzen-Faktor abgewogen werden muss.
Seiten ohne Performance-Probleme können auf eine View-all-Page zurückgreifen oder je nach Content-Volumen gänzlich auf die Content-Aufteilung auf Komponenten-Seiten verzichten. Hier sollte man dennoch regelmäßig die Ladezeit der Seite kontrollieren und schauen, ob Google nur die View-all-Page und nicht die paginierten Seiten indexiert.
Greift man nicht auf Infinite Scrolling zurück und eine View-all-Page ist aufgrund der Seitenperformance nicht geeignet, empfiehlt sich eine saubere Standard-Paginierung. Hier präferiere ich (und wahrscheinlich noch viele andere vom Fach) alle Seiten auf index, follow zu setzen.
Mit den oben vorgestellten Möglichkeiten einer Paginierung gibt es noch viele weitere Mischformen, die alle ihre Daseinsberechtigung haben. Habt ihr Beispiele aus der Praxis? Dann kommentiert diesen Artikel! Und bis dahin – next ➡️



Hi Jessica,
Klasse Artikel. Ist denn bei Nicht-Verwendung von noindex trotzdem gewährleistet das Seite 2 bis n nicht im Index auftauchen?
LG
Sebastian