AI vs. Human Translation
Für alle, die sich für die Funktionsweise dieses Prinzips interessieren, wird Christoph Henkelmann dieses Thema nun näher erläutern. Christoph ist technischer Geschäftsführer bei der DIVISIO GmbH und feilt täglich daran, KI fit für den kommerziellen Einsatz zu machen.
Das Word2Vec-Modell – semantische Repräsentation von Wörtern für künstliche Intelligenz
Künstliche Intelligenz (KI, auch Artificial Intelligence oder AI) ist in aller Munde, die Medien sind voll von apokalyptischen Zukunftsvisionen und überzogenen Versprechungen. Statt emotionalem Clickbait soll es aber hier um praktische Erklärungen zum besseren Verständnis dieser Technologie gehen, insbesondere darum, wie zeitgemäße maschinelle Übersetzung, wie z. B. Google Translate oder der DeepL Translator, funktioniert.
Wie sieht KI die Welt?
Die KI ist ein weites Feld, das über viele Jahre verschiedene Trends durchlebt und unterschiedliche Technologien hervorgebracht hat. Dinge, die vor Jahrzehnten als bahnbrechend und typisch für KI empfunden wurden, wie z. B. auf Großmeisterniveau Schach zu spielen oder komplizierte Gleichungen zu lösen, gelten heute als „typisch” für Computer und werden von uns gar nicht mehr als „intelligent” empfunden. Dies ist manchmal frustrierend für KI-Forscher: KI scheint immer das zu sein, was ein Computer nicht kann, sodass man per definitionem das Ziel nie erreichen kann, weil sich mit jedem Schritt nach vorne das Ziel mit verschiebt.
Machine Learning in der Übersetzung
In diesem Artikel wollen wir insbesondere ein spezielles Teilgebiet der KI betrachten, das zurzeit fast ausschließlich als „echte” KI betrachtet wird, auch wenn es sich nur um einen Teilbereich dieser Disziplin handelt: das Maschinelle Lernen (Machine Learning, ML). Anders als z. B. bei den Schachprogrammen der 90er Jahre, die all ihr Wissen und Können quasi von Hand einprogrammiert bekamen, wird beim ML ein allgemeiner KI-Algorithmus mit möglichst vielen Daten „trainiert“, bis er ein gewünschtes, spezielles Problem löst. Hierbei wiederum sind im Moment insbesondere tief vernetzte künstliche neuronale Netze (Deep Neural Networks, DNN) in Mode. Wir werden uns in diesem Artikel auf diese Art von KI (ML durch DNN) konzentrieren, es ist nur wichtig im Hinterkopf zu behalten, das KI auch anders funktionieren kann – auch wenn dies in der öffentlichen Diskussion derzeit gerne (auch in Fachkreisen) – vergessen wird.
Worte in Zahlen ausdrücken: Wie kann man Maschinen Sprache beibringen?
Praktisch alle ML-Algorithmen (und auch die meisten anderen KI-Verfahren) brauchen als Input Zahlen. Aller Input besteht aus Zahlenkolonnen einer festen Größe. Meist sind diese Zahlenkolonnen Vektoren (d. h. in einer Spalte fester Höhe notierte Zahlenwerte), manchmal sind die Zahlen auch in Rechtecken oder Quadern mit fester Höhe, Breite und ggfs. Tiefe angeordnet. Man spricht in diesem Fall von „Tensoren“.
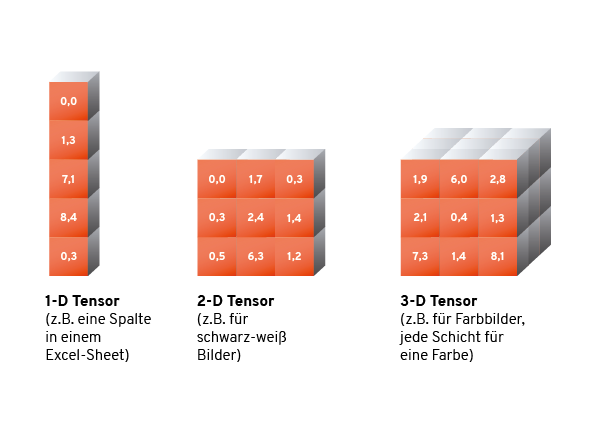
Bei tabellarischen Daten, z. B. Verkaufszahlen, einem Datum oder Prozentwerten, also allem was ohnehin numerisch in einem Excel-Sheet gespeichert werden kann ist die Darstellung als Zahlenkolonne leicht: Man kopiert einfach eine gewünschte Zeile oder Spalte und übergibt sie dem Algorithmus. Auch bei Daten, bei denen es nur eine begrenzte Auswahl von Werten gibt, kann man den einzelnen Optionen einfach fortlaufend Zahlenwerte zuordnen. Spielkarten kann man etwa wie folgt in Zahlen ausdrücken:
♢2 : 0
♢3 : 1
♢4 : 2
...
♢K : 10
♢A : 11
♡2 : 12
...
♣A : 51
Bilder in Zahlen ausdrücken: Wie Maschinen Bilder erfassen
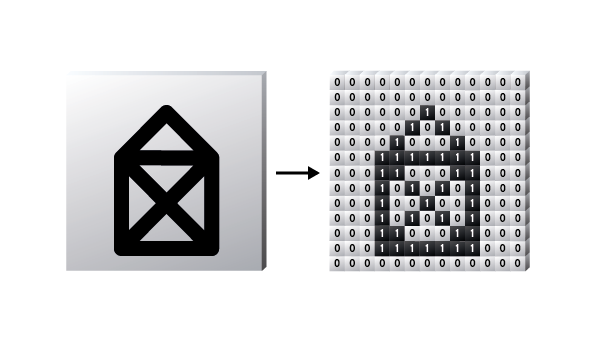
Auch bei Bildern ist diese Umwandlung in Zahlenkolonnen relativ klar: jeder einzelne Bildpunkt eines Bildes enthält bereits in Zahlen kodierte Farbwerte – dieser muss nur noch in einen rechteckigen Tensor geschrieben werden und kann so von einem ML-Algorithmus verstanden werden.
Vektorisierung von Text
Wie kann man nun Text sinnvoll in Zahlen verwandeln („vektorisieren” oder „kodieren“)? Naheliegend ist es natürlich zunächst, jedem Buchstaben eine Zahl zuzuordnen. So speichert ein Computer schließlich bereits Textdokumente – z. B. diesen Blog Post. Das würde dann so aussehen:
„Das ist das Haus vom Nikolaus.”
68 97 115 32 105 115 116 32 100 97 115 32 72 97 117 115
32 118 111 109 32 78 105 107 111 108 97 117 115 46
Hierbei werden Leerzeichen und Interpunktion einfach als eigene Buchstaben bezeichnet und bekommen ebenfalls eine Nummer. Diese Art von Darstellung hat aber zwei Probleme:
- Text hat unterschiedliche Längen, aber wie bereits erwähnt müssen unsere Zahlenkolonnen eine feste Größe haben.
- Buchstaben tragen keine semantische Bedeutung. Unsere KI müsste aus Buchstaben erst Wörter erkennen und dann Bedeutungen von Wörtern lernen – wir haben also unser Problem um eine weitere Schicht erweitert und uns von der automatischen Übersetzung ein Stück entfernt.
Für Problem 1 gibt es eine Reihe von Lösungen, die auch für andere Darstellungen gebraucht werden, aber Problem 2 ist schon kniffliger. Das ist genau der Grund, warum moderne Übersetzungsalgorithmen nicht auf der Buchstabenebene arbeiten. Meist sind reine Buchstabenkodierungen nicht sehr nützlich (Ausnahme: schnelle Bestimmung der Sprache eines Textes, um überhaupt zu wissen, zwischen welchen Sprachen man übersetzen muss).
Buchstaben sind zu feingranular und semantisch wenig nützlich, die Eingabe für ein ML-Verfahren muss also auf einer höheren Ebene kodiert werden, am besten für ganze Wörter. Hier kann man nun ähnlich vorgehen, wie bei Buchstaben: Man nimmt sich ein (sehr großes) Wörterbuch und nummeriert alle Wörter durch. Oft wird dies anhand des Textes gemacht, den man zum Trainieren nimmt: Ein Vorverarbeitungsschritt geht Wort für Wort durch den gesamten vorliegenden Trainingstext (z. B. die deutsche Wikipedia) und vergibt für jedes neue Wort eine neue Nummer. Die Nummerierung ist also mehr oder weniger zufällig. Das gibt z. B. folgende Beispielkodierung:
Das ist das Haus vom Nikolaus. 23 12 23 546 77 4096
Wir haben nun eine Kodierung auf Wortebene, aber auch eine ganze Reihe von neuen Problemen:
- Die Kodierungslänge ist immer noch variabel, aber die ML-Algorithmen wollen immer noch Input fester Größe.
- Unterschiedliche Formen des gleichen Wortes werden komplett anders kodiert, z. B. Haus = 546, Häuser = 2593, Hauses = 99483, …
- Die Nummerierung ist praktisch zufällig: Worte, die numerisch nah beieinander liegen, haben meist nichts miteinander zu tun.
Problem Nummer 1 wird, wie weiter unten erläutert, mit speziellen Umformulierungen des Lernverfahrens zu Leibe gerückt. Problem Nummer 2 wird für manche Probleme (z. B. Klassifikation von Text nach Textart) mittels sogenanntem Stemming und Stoppwörtern gelöst.
Was ist Stemming?
Stemming (vom englischen stem, also Stamm) führt ein Wort auf eine Grundform zurück:
Haus -> Haus Häuser -> Haus Hauses -> Haus ging -> gehen geht -> gehen geh -> gehen
Stoppwörter sind oft vorkommende Wörter und Bindewörter, diese werden bei Textklassifizierung oft einfach weggefiltert. Dazu gehören Artikel und sehr häufig verwendete Verben wie „haben“ oder „sein“.
„Das ist das Haus vom Nikolaus“ -> Haus Nikolaus „Dem gehört das Haus vom Nikolaus“ -> gehören Haus Nikolaus
Stemming sowie das Filtern von Stoppwörtern löst Problem 2 und ist sehr nützlich, wenn man Texte nur klassifizieren will („Ist das ein Vertrag oder ein Märchen?“, „Ist das Spam oder eine sinnvolle E-Mail?“), für die Übersetzung ist es aber tödlich: sehr wichtige semantische Informationen wie Plural, Zeitformen und Fälle gehen verloren, bevor überhaupt mit dem Übersetzen angefangen wird!
„Ich ging zum Haus vom Nikolaus“ -> „gehen Haus Nikolaus“ „Ich gehe zu den Häusern vom Nikolaus“ -> „gehen Haus Nikolaus“
Problem Nummer 3, die zufällige Nummerierung von Worten, ist damit auch noch nicht gelöst. Dies ist besonders unangenehm, wenn man betrachtet wie viele Lernverfahren, insbesondere neuronale Netze mit den Eingabewerten umgehen. Warum ist das so ein Problem, und wie kann man Text besser in Tensoren kodieren? Dazu erläutern wir Euch im Folgenden grob die Funktionsweise neuronaler Netze:
Machine Learning vs. menschliche Neuronen
Normalerweise wäre dies die Stelle, um Bilder von Neuronen zu zeigen und zu erzählen, wie moderne Algorithmen das menschliche Gehirn nachbauen. Nur leider ist dies falsch. Moderne DNN sind keine künstlichen Nachbauten des menschlichen Gehirns. Dieses Schauermärchen hilft, Interesse an der Materie zu wecken und verursacht das wohlige Gruseln, das Klickzahlen und Empörung nach oben treibt. Wie viele Unwahrheiten hat aber auch diese einen wahren Kern, den es sich zu erwähnen lohnt, der aber sachlich in den richtigen Kontext gesetzt werden muss.
Die initiale Inspiration für neuronale Netze sind in der Tat Vorgänge im Gehirn. Allerdings auf sehr grundlegender Ebene. Noch ist zu wenig über die Funktionsweise des Gehirns bekannt, um hier seriöse Vergleiche zwischen DNN und dem Gehirn zu ziehen. Nicht nur ist das Gehirn um viele Größenordnungen komplexer, auch grundlegende Mechanismen, wie z. B. das Lernen, funktionieren unglaublich viel effizienter im Gehirn als in ML-Algorithmen. Ein Beispiel: ein Griff auf eine heiße Herdplatte reicht i. d. R. für einen Menschen um für immer zu lernen, heiße Herdplatten nicht anzufassen. Ein KI-Lernalgorithmus müsste sich hunderte, vielleicht hunderttausende Male die Hand verbrennen, bis er dies wirklich gelernt hat. Das menschliche Gehirn ist unglaublich gut darin, aus sehr wenigen Einzelbeispielen zu abstrahieren und zu lernen. ML-Algorithmen brauchen wesentlich mehr Beispiele um zu verallgemeinern.
Das Pachinkogehirn
Ein passenderer Vergleich für ein neuronales Netz ist eher ein wahrhaft gigantischer, kilometerhoher Pachinko-Automat (eine Art japanischer Flipper, bei dem Kugeln oben in den Flipper geworfen werden und dann unbeeinflusst nach unten Fallen und an Hindernissen abprallen). Oben können in verschiedene Öffnungen Kugeln geworfen werden, unten fallen diese in unterschiedliche Behälter. In welchem Behälter die Kugeln landen hängt davon ab, wo im Riesenpachinko die Bälle abgeprallt sind.

Jeder Zahlenkolonne mit Input wird nun in den Automaten geworfen (die Zahlen repräsentieren die Anzahl und Position der Kugeln) und das Resultat mit dem gewünschten Ergebnis verglichen. Nach einigen Versuchen werden die Stäbchen und Hindernisse im Pachinko-Automaten nach gewissen Regeln verschoben, um das Ergebnis zu verbessern.

Wie lernt eine Maschine?
Mathematisch werden im Grunde nur immer wieder Zahlen multipliziert, addiert und mit null verglichen (von wenigen Ausnahmen, bei denen kompliziertere Funktionen vorkommen, einmal abgesehen). Daraus ergibt sich eine gigantische, komplexe, mehrdimensionale aber in den Einzelteilen eigentlich simple Formel. Mithilfe der gleichen Ableitungsregeln, die Ihr eventuell noch aus der Oberstufe kennt, wird die neue Position der „Pachinko-Stäbchen“ ausgerechnet. Diesen Prozess („Stochastic Gradient Descent“) nennt man „trainieren“ oder „lernen“. Der ML-Algorithmus wird initial zufällig initialisiert, probiert anhand einiger Beispiele aus, was zur Zeit berechnet wird, verschiebt einige Werte ein wenig um das Ergebnis zu verbessern, dann wird das ganze wiederholt. Oft millionen- oder milliardenfach (und öfter). Also weniger raffinierter Terminator, eher unendlich geduldiger Versuch und Irrtum.
Für Text hat dieses Vorgehen aber eine unangenehme Konsequenz: liegen zwei Wörter bezüglich ihres Zahlenwertes eng beieinander, fallen sie an ungefähr der gleichen Stelle (mit ähnlicher Geschwindigkeit, in ähnlichem Winkel etc.) in unser Pachinko-Gehirn. Die Kugel hat also eine ähnliche Flugbahn. Bei ähnlichen Wörtern kann dies sogar sinnvoll sein, um semantische Nähe auszudrücken. Aber die Zahlenwerte für Wörter sind ja komplett zufällig gewählt. Es ist also eine schlauere Kodierung von Wörtern nötig.
Semantische Beziehungen von Wörtern
Manchmal sollten die Zahlendarstellungen von Wörtern also ähnlich sein, und manchmal unterschiedlich, und das mit System. Jetzt könnten Wörter mit viel, viel Mühe auf einer Zahlengeraden angeordnet werden, und dann nummeriert. Zum Beispiel: erst alle Nomen, dann alle Verben, etc., innerhalb der Nomen z. B. nach konkreten Dingen (Haus, Tier, …) und nach abstrakten Konzepten sortiert (Ehre, Verantwortung, …), usw. usf. immer feiner.
Baum, Strauch, Blume, Stein, .... (einige zehntausend Wörter) ... ...ich, du, er, sie, es... (viele weitere Wörter) ... ...sein, bin, bist, ist, sind, seid, war, waren, ....
Dies ist schon wesentlich schöner sortiert, und ähnliche Wörter stehen in der Tat beieinander, aber ein einfaches Beispiel zeigt schon die Probleme. Je nachdem, welchen Aspekt eines Wortes man betrachtet, sind sich Wörter gleichzeitig ähnlich und unähnlich.
Etwa die Wörter „Hund“ und „Katze“:
- ähnlich: beides sind Tiere mit vier Beinen, beides sind sogar Haustiere, beides Säugetiere, beide mit Fell, beide Wörter sind Nomen im Singular
- unähnlich: bekannterweise werden Hund und Katze gerne exemplarisch als Sinnbild für Unterschiedlichkeit herangezogen.
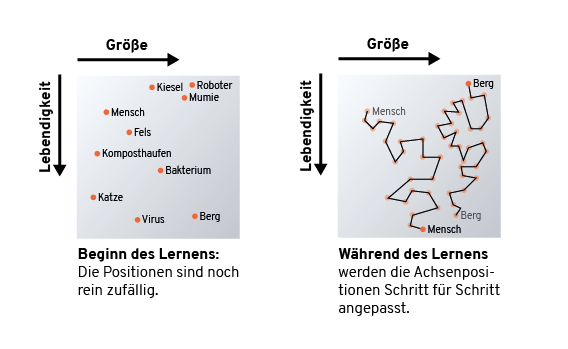
Die Wörter sind also gleichzeitig ähnlich (grammatikalisch wie inhaltlich) als auch Ausdruck von krassem Gegensatz. Worte müssen also anhand mehrerer Achsen sortiert werden. Zwei solche Achsen könnten z. B. „Lebendigkeit“ und „Größe“ sein.
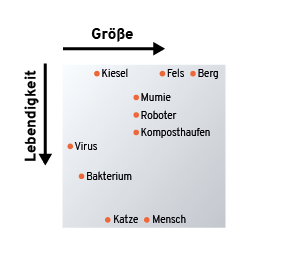
Jetzt reicht es aber nicht mehr, eine einzelne Zahl pro Wort zu wählen, wir haben mehrere Koordinaten pro Wort (je nach Anzahl der „Bedeutungsachsen“), also einen Vektor oder eine Zahlenkolonne. Aber das macht nichts, ML-Algorithmen können ja sehr gut mit Zahlenkolonnen arbeiten. Wörtern solche Positionen auf mehreren Achsen zuzuordnen, nennt man eine „Einbettung“ (Embedding).
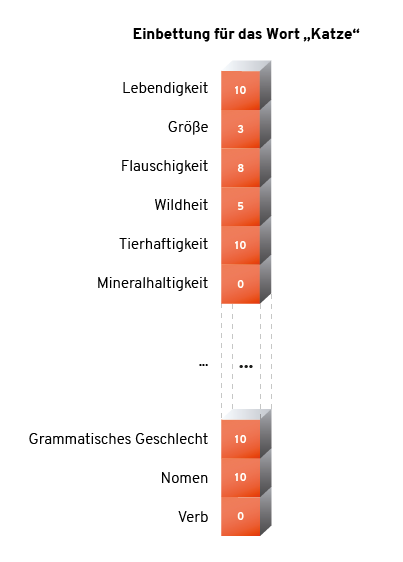
Eine solche Einbettung löst die oben aufgeführten Probleme 2 und 3: ähnliche/unterschiedliche Wörter liegen (je nach Art der Ähnlichkeit/Unähnlichkeit) auf manchen Achsen nahe beieinander, auf anderen weit entfernt. Die Positionen sind auch nicht mehr zufällig, sondern semantisch sinnvoll. Aus einer für die Maschine unsinnigen Kette von Buchstaben wird so eine Zahlenkolonne, die in ihrer Struktur Sinn kodiert.
Word2Vec und Embeddings: Die Basis für die KI-gestützte Übersetzung
Nun ist leicht ersichtlich, dass es vieler solcher Achsen bedarf, um die vielfältigen Beziehungen von Wörtern zu kodieren (Plural/Singular, groß/klein, schnell/langsam, wild/zahm, abstrakt/konkret, Tier/Pflanze, …). Auch ist es eine enorme Arbeit, hunderttausende Wörter einer Sprache so zu erfassen, eine Mammutaufgabe. Aber hier kommt ML zur Hilfe: Was, wenn man eine Maschine diese Einbettung lernen lassen könnte? Dafür gibt es den raffinierten Word2Vec-Algorithmus.
Initial wird durch die Entwicklerin entschieden, wie viele Achsen (Dimensionen) die entstehende Einbettung haben soll. Dann wird für jedes Wort ein zufälliger Vektor mit Achsenkoordinaten gewählt. Dies hört sich zunächst unsinnig an, aber hier hilft uns das Bild vom Pachinko-Automaten und dem schrittweisen Anpassen der Stäbchen und Hindernisse: Der Word2Vec-Algorithmus verschiebt ganz allmählich tausende Wörter auf hunderten Achsen, bis das Ergebnis Sinn ergibt.
Aber woher soll Word2Vec wissen, wann eine Einbettung sinnvoll ist? Dazu müsste ein Mensch wieder Unmengen an Beispielen zum Lernen erstellen. Hier hilft eine simple Erkenntnis und ein raffinierter Trick: Wörter die in ähnlichen Textschnipseln an ähnlichen Stellen verwendet werden, haben eine ähnliche Bedeutung. Word2Vec wird mit einem riesigen Textkorpus trainiert und muss Lücken in Textschnipseln füllen. Dieser Lückentext lässt sich automatisch aus jedem Textkorpus erzeugen. Z. B.:
Textkorpus: Das ist das Haus vom Nikolaus. Es hat ein rotes Dach. Lückentexte & Lösung: das ist _ Haus vom → das ist das _ vom Nikolaus → Haus ... Es hat _ rotes Dach → ein
Nun müssen keine Lerndaten manuell erstellt werden: Man kann einfach den ganzen Text zerschneiden und damit Word2Vec trainieren. Nach einigen dutzend Schritten passt Word2Vec die Achsenpositionen der an den Beispielen beteiligten Wörter an, um die eigenen Fehler zu reduzieren. So entstehen – nach einigen Milliarden Schritten – semantisch sinnvolle Einbettungen ganzer Sprachen in hunderte Achsen. Diese Einbettungen können nun endlich genutzt werden, um einen Übersetzer zu trainieren. Die Ähnlichkeiten und Unähnlichkeiten der Einbettung kann die eigentliche Übersetzungs-KI nutzen, um besser mit Mehrdeutigkeiten, Synonymen u. Ä. umzugehen. Und aufgrund der vielen Achsen ist die Darstellung auch robust gegen kleinere Abweichungen in der „Position der Pachinko-Kugeln“.
Die faszinierenden Eigenschaften von Word2Vec-Einbettungen
Wie der Name schon sagt, erzeugt Word2Vec eine Abbildung von Wörtern in Zahlenkolonnen (Word2Vec – Wort zu Vektor). Die Bezeichnung Vektor wird nicht nur gewählt, weil wir es mit einer Spalte Zahlen (Positionen auf Achsen) zu tun haben, wir können die entstehenden Vektoren auch benutzen wie Vektoren in der Schule. Nur statt Schnittpunkte von Linien zu berechnen, können wir folgende Fragen lösen:
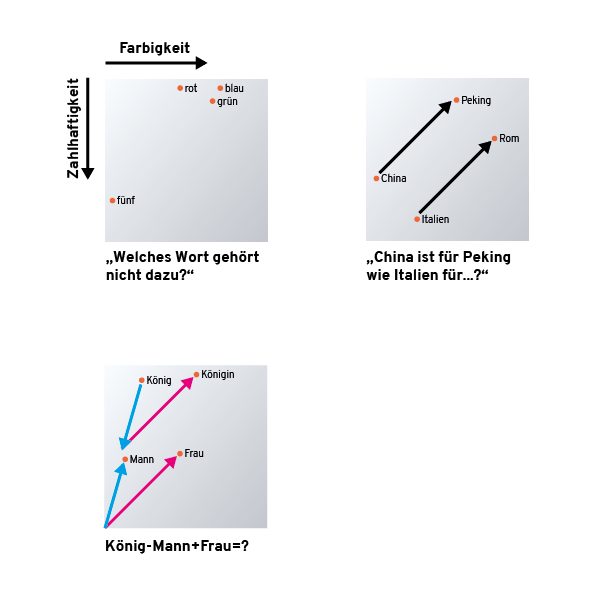
Eine gut trainierte Word2Vec-KI kann diese Fragen durch einfaches Addieren und Subtrahieren von Vektoren und durch Abstandsberechnung lösen. Einfach nur durch die Achsenkoordinaten, die den Wörtern zugeordnet wurden. Die „KI“ ist am Ende nur eine große Tabelle von Koordinaten und eine Sammlung von Grundrechenarten und Trigonometrie. (Und hat nebenbei bemerkt bestimmt keine Ambitionen auf die Weltherrschaft).
Mit Word2Vec als „Eingabesystem“ für eine Übersetzungs-KI haben wir einen großen Schritt in Richtung maschinelle Übersetzung gemacht. Ein maschineller Übersetzer benutzt zwei Word2Vec-Einbettungen, eine für die Ursprungssprache und eine für die Zielsprache. Diese werden wie Adapter zwischen den Übersetzer und die Eingabe und Ausgabe geschaltet, sodass für die Übersetzungs-KI Wörter wie Punkte in hochdimensionalen Räumen erscheinen. Dies mag für uns Menschen äußerst unintuitiv sein, aber ein ML-Algorithmus arbeitet am besten auf langen Zahlenkolonnen also Vektoren. Wie wird aber nun das Problem gelöst, dass wir ganze Sätze übersetzen wollen, nicht nur einzelne Wörter – denn dafür gibt es schon lange elektronische Vokabeltrainer, die das prima hinbekommen, ganz ohne KI, nur mit Vokabellisten.
Sätze beliebiger Länge
Der KI-Pachinko-Automat kann immer nur einzelne Problem der Form „Input fester Größe, Output fester Größe“ lösen. Nachdem ein Problem gelöst wurde, ist alles wie vorher, wie ein Pachinko-Automat hat ein neuronales Netz kein Gedächtnis – nur die Positionen für die Hindernisse der Kugeln. Eine erste Idee wäre, einfach eine maximale Anzahl Eingabe- und Ausgabewörter zu erlauben und so zumindest Sätze bis zu einer gewissen Länge zu übersetzen, indem man die Zahlenkolonnen aller Wörter einfach aneinanderklebt. Unbenutzte Plätze für Wörter werden dabei auf null gesetzt. Dies hat jedoch zwei signifikante Nachteile:
- Die Länge der Sätze wird limitiert.
- Die Größe des Pachinkogehirns wächst exponentiell und braucht ewig zum Trainieren – und das bei einem schlechten Ergebnis.
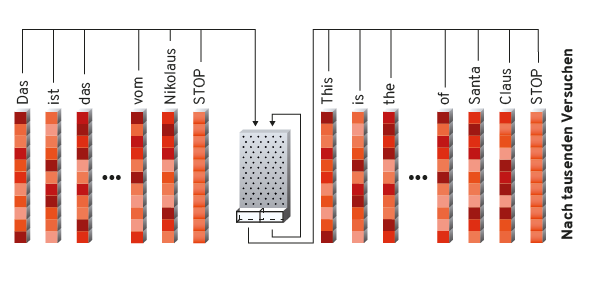
Insbesondere Punkt 2 macht diese Idee in der Praxis nicht einsetzbar. Aber es gibt einen anderen Trick: Man gibt dem Pachinkogehirn eine zusätzliche Zahlenkolonne als Input und Output, die es beliebig benutzen kann. Der zusätzliche Output wird vom Pachinkogehirn genutzt, um sich Dinge zu merken. Der zusätzliche Input wird genutzt, damit beim erneuten Hereinwerfen von Kugeln das Gehirn weiß, was es sich merken wollte.
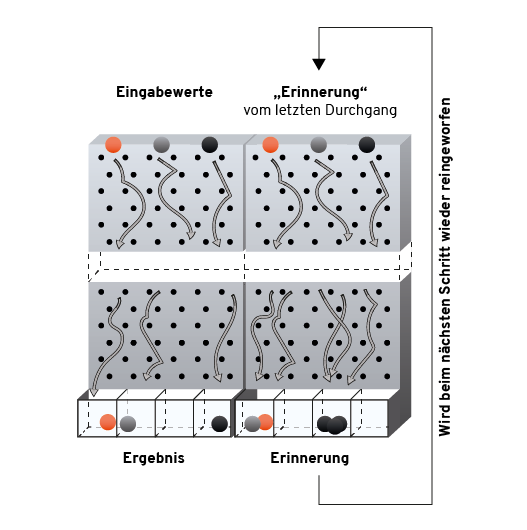
Es wird einfach Wort für Wort eines Satzes oben in die Pachinko-Maschine geschüttet. Zusammen mit dem Wort wird der „Notizzettel“, der beim vorigen Schritt herausgefallen ist, wieder mit hineingekippt, damit das Pachinkogehirn weiß, wo es im Satz steht, was es bereits gesehen hat usw. Das Ende des Satzes markieren wir einfach mit einem speziellen magischen Wort, dem „Stoppwort“. Dies kann z. B. eine Zahlenkolonne nur mit Nullen sein, die sich deutlich von den „echten“ Wörtern abhebt. Sobald das Stoppwort hineingekippt wurde, kippen wir nur noch Nullen und Notizzettel in das Pachinkogehirn. Dieses gibt dann Wörter in der Zielsprache aus, bis es selber denkt, es sei fertig und selbst das Stoppwort ausspuckt.
Trainieren des Übersetzers
Für einen Übersetzer braucht es also zwei trainierte Word2Vec-Einbettungen für Ursprungs- und Zielsprache und viele, viele Beispiele für übersetzte Sätze. Das Training läuft jetzt wieder wie bei allen neuronalen Netzen, genau wie bei Word2Vec oder der allgemeinen Erläuterung am Anfang des Artikels. Der Übersetzer wird zufällig initialisiert – die „Hindernisse“ des Pachinko-Automaten werden einfach irgendwo hingesetzt. Dann werden die ersten Sätze in das System gegeben. Anfangs weiß das System nicht mal, dass es einen Satz mit einem Stoppwort beenden muss, wenn es fertig ist. Es spuckt kompletten Unsinn aus.
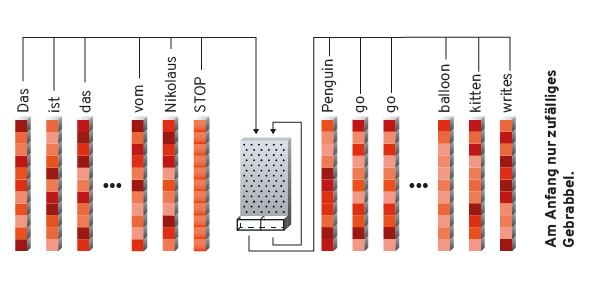
Dieser Unsinn wird mit der eigentlichen Zielübersetzung verglichen. Da nicht mit Wörtern gearbeitet wird – Word2Vec gibt uns ja Zahlenkolonnen – kann der zahlenmäßige Unterschied zwischen dem Unsinn und der tatsächlichen Übersetzung berechnet werden. Dieser wird nach einigen Schritten benutzt, um das Pachinkogehirn ein wenig in die richtige Richtung zu verändern. Dann wird wiederholt – wieder, wieder, und wieder.
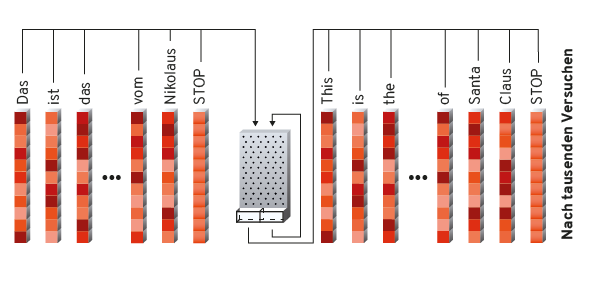
Das fertige System
Die maschinellen Übersetzer, wie sie hier beschrieben wurden, sind die Basis für z. B. Google Translate. Die Tatsache, das diese Systeme mit Satzpaaren trainiert werden, erklärt eines der größten Mankos dieser Systeme: Der maschinelle Übersetzer denkt nicht über das Ende des Satzes hinaus und hat Probleme Zusammenhänge zu erfassen, die sich über mehrere Sätze ziehen, oder Referenzen auf andere Teile des Textes. Ein einfaches Beispiel aus Google Translate zeigt das sehr deutlich:
Originaltext auf Deutsch: Der Mond ist aufgegangen. Er leuchtet hell. Google Übersetzung nach Französisch: La lune s'est levée. Il brille de mille feux.
Im ersten Satz wird „der Mond“(männlich) korrekt mit „la lune“ (weiblich) übersetzt. Der Google-Übersetzer weiß, dass „Mond“ im Französischen ein weibliches Nomen ist (vermutlich dank der Word2Vec-Einbettung der französischen Sprache). Aber schon im zweiten Satz hat der Übersetzer dies vergessen: „Il“ (Er) statt „Elle“ (Sie).
Nichtsdestotrotz ist die aktuelle Leistung der maschinellen Übersetzung schon beachtlich, insbesondere wenn man einmal einen Blick unter die Haube geworfen hat und merkt, dass da eigentlich nur Zahlenkolonnen durch schrittweise erratene Abläufe geschickt werden.
Allerdings gibt es bereits ein neues Forschungsergebnis von Microsoft Research, dass – zumindest laut der Verfasser – auch für längere Texte Übersetzungen liefert, die mit professionellen Übersetzern mithalten können. Und dies ausgerechnet für eine Übersetzung von Englisch nach Chinesisch, nicht gerade einem leichten Sprachpaar. Es wird spannend zu sehen, wie lange es dauert, bis diese neue Generation von Übersetzern online zugänglich ist und wie sie sich in der Praxis schlägt.


